
今回は畳み込みニューラルネットワーク(CNN)の実装についてのアウトプットです。
E資格受験時にCNNについてはライブラリなしでコーディングできるほど学んだ記憶はあるのですが、それ以降画像分類など一度もしたことがなかったので良い復習の機会になりました。
専門用語がいくつか出てきますが、それぞれについて補足すると膨大な量になるので、ここでは実装の流れに特化して記載します。気になる用語があれば調べてみてください。
損失関数
kerasでは損失関数の利用にはlossesモジュールを使い、モデルにセットするときにはcompileを使う。
from keras import losses
model.compile(loss=losses.mean_squared_error, optimizer=SGD)損失関数は回帰分析にはMSEを、二値分類にはBCEを、多値分類にはCEを使うことが多い。
(CE:クロスエントロピー誤差)
損失関数の最小値探索方法は「ミニバッチ確率的勾配降下法」が考え方の基本。
→ただしMomentum、Adam、AadGradなどの最適化関数がその後考案されている(各関数の詳細は長くなるのでここでは省略)
CNNの実装
CNNをkerasで実装するためのライブラリは以下の3つ
- Conv2D:2次元の畳み込み層を実装
- MaxPooling2D:2次元のプーリング層を実装
- Flatten:入力を1次元に変換
サンプルコード
# ライブラリのインポート
from keras.models import Sequential
from keras.layers import Dense, Flatten, Activation
from keras.layers import Conv2D, MaxPooling2D
model = Sequential()
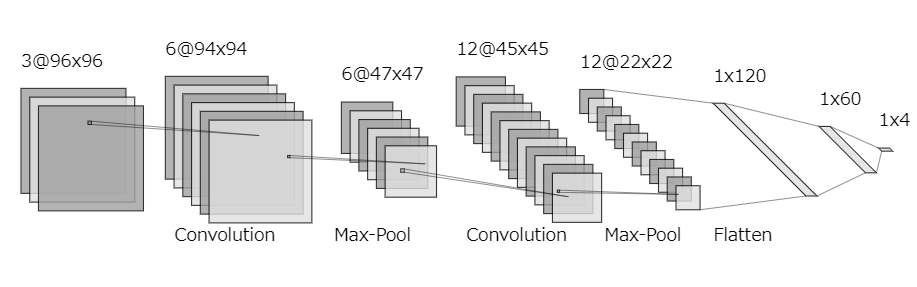
# 畳み込み層(フィルタサイズ=6, カーネルサイズ=(3,3), 入力サイズ=(96,96,3))
# 画像の特徴を捉えるための層
model.add(Conv2D(filters=6, kernel_size=(3, 3), input_shape=(96, 96, 3)))
# 活性化関数
# 非線形性をモデルに導入するための関数
model.add(Activation("sigmoid"))
# プーリング層(サイズ=(2,2))
# データの次元を削減し、過学習を防ぐための層
model.add(MaxPooling2D(pool_size=(2, 2)))
# もう一度畳み込み、活性化、プーリングを繰り返し
model.add(Conv2D(filters=12, kernel_size=(3, 3)))
model.add(Activation("sigmoid"))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 1次元化
# 畳み込みとプーリングによって得られた特徴マップを1次元のベクトルに変換
model.add(Flatten())
# 全結合層以降ニューラルネットワークと一緒
# 全結合層は、特徴を組み合わせて最終的な分類を行う
model.add(Dense(units=120))
model.add(Activation("sigmoid"))
model.add(Dense(units=60))
model.add(Activation("sigmoid"))
model.add(Dense(units=4))
model.add(Activation("softmax")) # 最後の層ではsoftmax関数を使うことで、出力を確率に変換
モデル学習
学習率やオプティマイザ先述の通り設定した後、バッチサイズやエポック数を指定して学習を行う。
log = model.fit(X_train, y_train, batch_size=10, epochs=5, validation_data=(X_val, y_val))
獲得したログから「損失関数とエポック数」「正解率とエポック数」の推移をグラフ化してモデルの性能を確認する。
モデル改善
活性化関数の変更
モデル改善の一案は活性化関数の変更。上の例であればsigmoidをReLuに変える(model.add(Activation(“relu”)))。
学習率の変更
学習率の変更も性能改善の有効な手段。SIGNATEの講義内では学習率を0.5から0.05に変えただけで大幅に改善した。(こちらももともと0.5は高過ぎる数字ではあるものの、変化を見る意味では有用だった)
モデルの深層化
SIGNATEの講義内では畳み込みとプーリングの1セットを追加したら、lossの減少と正解率の増加が見られたことを確認。
オプティマイザの変更
講義ではSGDからAdaGradに変更(optimizer=optimizers.Adagrad(lr=0.01))することで大きく変化することを確認。
CNNは実践で使ったことはないので、今後実践するにあたって不足していることがあれば随時足していきます。


