
本記事では、ニューラルネットワークの実装についての基本的な流れを解説します。
ニューラルネットワークの基礎知識
ニューラルネットワークの理解を深めるために、その基本的な概念と機能について簡単に説明します。
ニューラルネットワークは、人間の脳の神経細胞(ニューロン)の動作を模倣した機械学習のモデルです。ニューロンは、複数の入力を受け取り、それらを処理して出力を生成します。同様に、ニューラルネットワークの各ノード(人工ニューロン)は複数の入力を受け取り、それらを重み付けして合計し、活性化関数を通じて出力を生成します。
活性化関数はノードの出力を決定するための関数で、非線形性をモデルに導入します。よく使用される活性化関数には、シグモイド関数、ハイパボリックタンジェント関数、ReLU(Rectified Linear Unit)関数などがあります。
ニューラルネットワークの学習は、訓練データを使用してモデルの重みを調整するプロセスです。モデルの出力と目標出力との間の差(誤差)を計算し、この誤差を最小化するように重みを更新します。このプロセスは、勾配降下法と呼ばれる最適化アルゴリズムを使用して行われます。
以下に、ニューラルネットワークの基本的な構造を示すコードを示します。
from keras.models import Sequential
from keras.layers import Dense
# モデルの定義
model = Sequential()
# 入力層と隠れ層の追加
model.add(Dense(512, activation='relu', input_shape=(28 * 28,)))
# 出力層の追加
model.add(Dense(10, activation='softmax'))
このコードはニューラルネットワークの基本的な構造を示しています。モデルはSequentialクラスのインスタンスで、これに各層(Denseクラスのインスタンス)を追加していきます。各層は、活性化関数とともに定義されます。
Kerasを用いたニューラルネットワークの基本的な実装手順
ニューラルネットワークの実装には、一般的に4つのステップ:モデルの定義、コンパイル、訓練、そして予測が必要です。それぞれのステップが何を意味し、なぜ重要なのかを詳しく見ていきましょう。
- モデルの定義:このステップでは、ニューラルネットワークのアーキテクチャを定義します。つまり、どのような種類の層をどの順序で配置するか、各層には何個のノードを設定するかなどを決定します。これは、建物を建てる際の設計図を作成するようなもので、ニューラルネットワークの基本的な形状と機能を決定します。
- コンパイル:モデルの定義が完了したら、次にモデルをコンパイルします。このステップでは、損失関数(モデルの予測がどれだけ正解から外れているかを測定する関数)と最適化アルゴリズム(損失関数を最小化するための手法)を選択します。また、訓練の進行状況を監視するための評価指標も選択します。
- 訓練:コンパイルが完了したら、モデルを訓練データで訓練します。訓練とは、モデルに入力データを与えて予測をさせ、その予測が正解からどれだけ外れているか(損失)を計算し、その損失を最小化するようにモデルのパラメータを更新するプロセスのことです。このプロセスを繰り返すことで、モデルはデータからパターンを学習し、予測性能を向上させます。
- 予測:モデルの訓練が完了したら、未知のデータに対する予測を行います。これは、モデルが学習したパターンを用いて新たな問題を解く能力を試すステップです。
以上がニューラルネットワークの基本的な実装手順です。それぞれのステップは、モデルがデータからパターンを学習し、その学習したパターンを用いて新たな問題を解くための重要なプロセスです
さて、それではこの概念を元にどのように実装をしていくのか、具体的な手順を説明をしていきます。
ニューラルネットワークの実装には、KerasというPythonの深層学習ライブラリを使用します。Kerasは、ニューラルネットワークの構築と訓練を簡単に行うことができる高レベルAPIを提供しています。
モデルの定義
ニューラルネットワークのモデルを定義します。Kerasでは、Sequentialモデルを使用してニューラルネットワークを定義します。Sequentialモデルは、各層が直列に接続された単純なニューラルネットワークを表します。
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential()
model.add(Dense(20, input_shape=(31,))) # 入力層(ノード数は20、入力サイズは31)
model.add(Activation('relu')) # 活性化関数(ReLU)
model.add(Dense(100)) # 隠れ層(ノード数は100)
model.add(Activation('relu')) # 活性化関数(ReLU)
model.add(Dense(1)) # 出力層(ノード数は1)
model.add(Activation('sigmoid')) # 活性化関数(シグモイド)
コンパイル
次に、モデルのコンパイルを行います。コンパイルでは、損失関数、最適化アルゴリズム、および評価指標をモデルに設定します。
model.compile(optimizer='rmsprop',
loss=<span class="hljs-string">'binary_crossentropy'</span>,',
metrics=['accuracy'])
訓練
モデルの訓練は、fitメソッドを使用して行います。fitメソッドは、訓練データとその対応するラベル、エポック数(訓練データを何回繰り返すか)、バッチサイズ(一度に処理するデータの数)を引数に取ります。
model.fit(train_data, train_labels, epochs=10, batch_size=32)
予測
最後に訓練したモデルを使用して新しいデータに対する予測を行います。predictメソッドを使用して新しい入力データに対するモデルの出力を生成します。
predictions = model.predict(new_data)
以上が、Kerasを用いたニューラルネットワークの詳細な実装手順です。この手順を通じて、ニューラルネットワークの構築、訓練、評価、予測を行うことができます。
実際のデータセット(MNIST)を用いたニューラルネットワークの訓練
次に、実際のデータセットを用いてニューラルネットワークの訓練を行ってみます。ここでは手書き数字の画像データセットであるMNISTを使用します。MNISTは、機械学習の世界で非常によく使用されるデータセットで、0から9までの手書き数字の画像28×28ピクセルのグレースケール画像60,000枚と、それに対応するラベルから成り立っています。
まず、Kerasを使用してMNISTデータセットをロードします。KerasのデータセットモジュールにはMNISTが含まれており、簡単に利用することができます。
次に、データの前処理を行います。画像データは通常、0から255の整数値を持つピクセル強度で構成されていますが、ニューラルネットワークに入力する前にこれらの値を0から1の範囲にスケーリングします。また、ラベルデータ(0から9の整数)をカテゴリカル形式に変換します。
これらの前処理を行った後、先ほど構築したニューラルネットワークモデルにデータを適用します。モデルの訓練は、fitメソッドを使用して行います。このメソッドは訓練データとラベルデータ、エポック数(訓練データを何回繰り返して学習するか)、バッチサイズ(一度に処理するデータの数)を引数として受け取ります。
コードは以下のような形になります。
# 必要なライブラリをインポート
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense
# MNISTデータセットをロード
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# データの前処理
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# モデルの構築
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(28 * 28,)))
model.add(Dense(10, activation='softmax'))
# モデルのコンパイル
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# モデルの訓練
model.fit(train_images, train_labels, epochs=5, batch_size=128)
ここで、訓練データとテストデータの違いと、それぞれがなぜ必要なのかについても触れていきます。
訓練データとテストデータの違い
訓練データとテストデータは、それぞれ異なる目的で使用されます。訓練データは、モデルがデータからパターンを学習するために使用されます。一方、テストデータは、モデルが未知のデータに対してどれだけ良い予測を行うことができるかを評価するために使用されます。つまり、訓練データはモデルの学習に使用され、テストデータはその学習結果の評価に使用されます。
訓練データとテストデータがなぜ必要なのか
訓練データとテストデータの分割は、モデルが過学習(overfitting)を起こしていないかを確認するために重要です。過学習とは、モデルが訓練データに対しては高い性能を示すものの、新しいデータに対しては低い性能を示す状態を指します。訓練データだけでなくテストデータも用意することで、モデルが新しいデータに対しても良好な性能を発揮することを確認できます。
モデルの訓練と予測: 実践的なステップ
モデルの訓練が完了したら、次は予測を行います。予測は、訓練されたモデルを使用して新しいデータ(この場合はテストデータ)に対する出力を生成するプロセスです。Kerasでは、model.predict()メソッドを使用して予測を行います。このメソッドは新しい入力データを引数として受け取り、それぞれの入力に対するモデルの出力を返します。
さらにモデルの性能を評価するためには、テストデータを使用してモデルの精度を計算します。Kerasでは、model.evaluate()メソッドを使用してモデルの性能を評価できます。このメソッドはテストデータと対応するラベルを引数として受け取り、モデルの損失値とメトリクス値(この場合は精度)を返します。
以下に、予測と評価のコードを示します。
# モデルを使用して予測を行う
predictions = model.predict(test_images)
# 最初の予測を表示
print(predictions[0])
# モデルの性能を評価する
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)

このコードは訓練されたモデルを使用してテストデータに対する予測を生成し、その後でモデルの精度を評価しています。これにより、モデルが未見のデータ(test)に対してどの程度正確に予測できるかを確認できます。
モデルの可視化
モデルの訓練と評価が完了したら、次にモデルの構造を可視化してみます。モデルの可視化は、モデルの構造を理解し、どのようにデータがネットワークを通過するかを把握するのに役立ちます。
Kerasでは、model.summary()メソッドを使用してモデルの構造を簡単に表示できます。このメソッドは、モデルの各層の名前、出力形状、およびパラメータ数を一覧表示します。これにより、モデルの大まかな構造と規模を把握することができます。
さらに詳細な可視化を行いたい場合は、Kerasのplot_model関数を使用することもできます。この関数は、モデルの各層の詳細な図を生成します。
以下に、モデルの可視化のコードを示します。
# モデルの構造を表示
model.summary()
# モデルの図を生成(オプション)
from keras.utils import plot_model
plot_model(model, to_file='model.png')
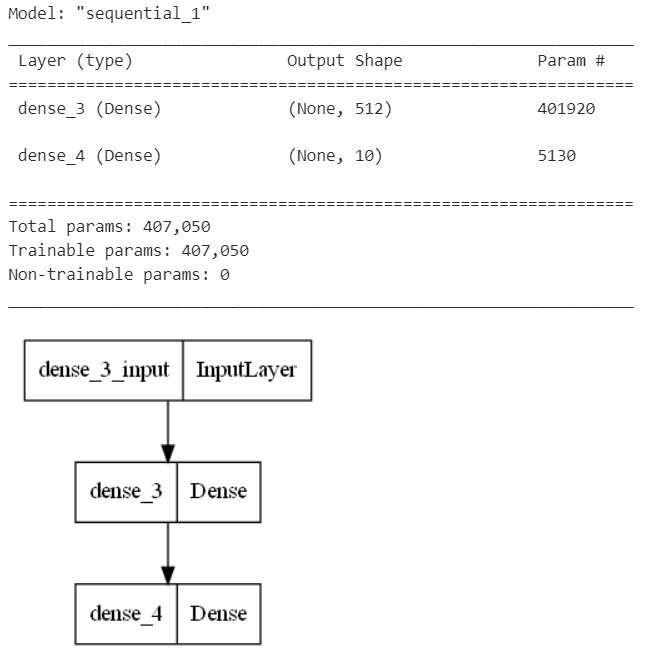
このコードは、model.summary()メソッドを使用してモデルの構造を表示し、plot_model関数を使用してモデルの図を生成しています。これにより、モデルの構造と動作をより深く理解することができます。
回帰と分類の違い
ニューラルネットワークは、回帰問題と分類問題の両方に使用できます。これらは、予測される出力の種類によって異なります。
分類問題では、モデルは入力データが与えられたいくつかのカテゴリのうちどれに属するかを予測します。例えば手書きの数字の画像が与えられた場合、モデルはその画像が0から9のどの数字を表しているかを予測します。分類問題では通常、出力層の活性化関数としてソフトマックス関数を使用し、損失関数としてクロスエントロピーを使用します。
一方回帰問題では、モデルは入力データに基づいて連続的な数値を予測します。例えば、家の特徴(広さ、部屋の数、立地など)が与えられた場合、モデルはその家の価格を予測します。回帰問題では通常、出力層の活性化関数として恒等関数(または何も使用しない)を使用し、損失関数として平均二乗誤差を使用します。
以下に、分類問題と回帰問題のためのモデルの設定例を示します。
# 分類問題のためのモデル
model_classification = Sequential()
# 隠れ層では、ReLU(Rectified Linear Unit)などの非線形活性化関数が一般的に使用されます。
model_classification.add(Dense(512, activation='relu', input_shape=(28 * 28,)))
# 分類問題の出力層では、ソフトマックス活性化関数が一般的に使用されます。
# ソフトマックス関数は、各クラスに属する確率を出力します。
model_classification.add(Dense(10, activation='softmax')) # ソフトマックス活性化関数
# 分類問題では、クロスエントロピー損失関数が一般的に使用されます。
# これは、モデルの予測が正解ラベルとどれだけ一致しているかを測定します。
model_classification.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) # クロスエントロピー損失関数
# 回帰問題のためのモデル
model_regression = Sequential()
# 回帰問題でも、ReLUなどの非線形活性化関数が一般的に使用されます。
model_regression.add(Dense(512, activation='relu', input_shape=(10,)))
# 回帰問題の出力層では、通常、恒等活性化関数(つまり、何もしない関数)が使用されます。
# これは、回帰問題では任意の実数値を出力できる必要があるためです。
model_regression.add(Dense(1)) # 恒等活性化関数(何も指定しない)
# 回帰問題では、平均二乗誤差損失関数が一般的に使用されます。
# これは、モデルの予測が正解値とどれだけ離れているかを測定します。
model_regression.compile(optimizer='rmsprop', loss='mse') # 平均二乗誤差損失関数
上記のコードは、分類問題と回帰問題のためのモデルの設定を示しています。これにより、同じニューラルネットワークが異なる種類の問題にどのように適応できるかを理解できます
この記事ではKerasを用いた実装方法を紹介しましたが、ニューラルネットワークの理解を深めるためには、ライブラリを使わずに実装する力も必要です。特にE資格ではそのようなスキルが求められました。ニューラルネットワークの構造までしっかり理解したい人は、“ゼロから作るDeep Learning”(通称ゼロつく)などの書籍を読むことをお勧めします。この書籍をしっかりと理解すれば、ニューラルネットワークの実装に必要な知識を十分に身につけることができます。


