
今日はPythonのライブラリであるPandasを使ってExcel表データを読み込み、前処理を行う方法について学んだことを共有します。
データコンペやAIの講義などではcsvで整形されたデータを読み込むところから前処理を始めるケースも多いですが、実際にはExcelで作成した表を読み込むようなケースが想定されますので、このような方法も知っておくと便利だと思いました。
なお、学んだ講座で題材としていたのは「沖縄県の推計人口データ」のファイルですので、こちらを参照するとイメージが湧くと思います。
(以下は令和5年5月のファイルより抜粋)
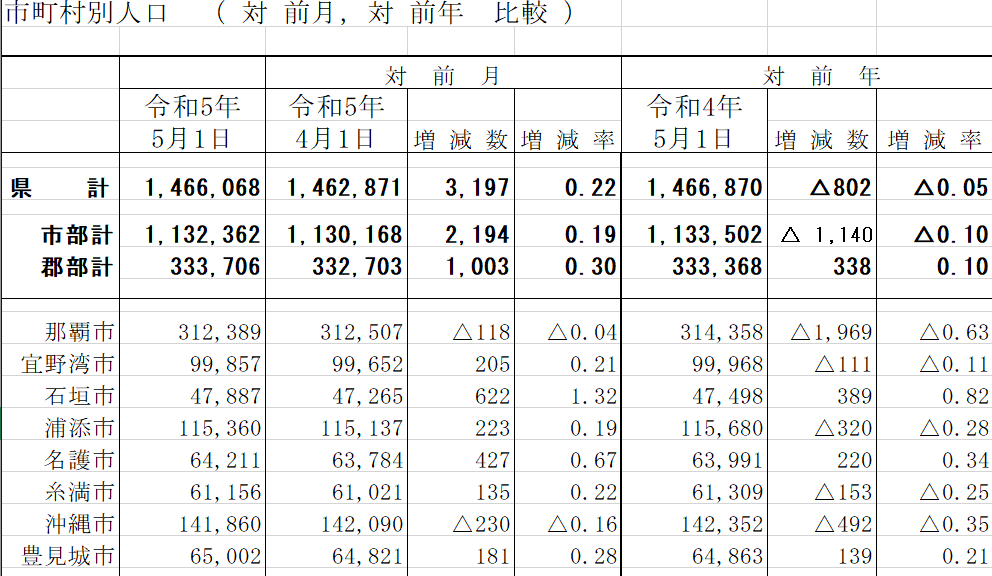
Excelの表データの読み込み
まずは、Excelファイルからのデータ読み込みから。
Pandasのread_excel関数を使うと、Excelファイルから直接データを読み込むことができる。以下のようにioパラメータにファイル名を、sheet_nameパラメータにシート名を指定する。
df_data = pd.read_excel(io='ファイル名', sheet_name='シート名')
データの確認
次に、読み込んだデータの行数と列数を確認する。Pandasのshape属性を使うと、データフレームの行数と列数をタプル形式で取得できる。以下のようにshape[0]で行数、shape[1]で列数をそれぞれ取得できる。
print(df_data.shape) # 行数と列数を表示
print(df_data.shape[0]) # 行数を表示
print(df_data.shape[1]) # 列数を表示
ヘッダーの整形
Pandasでは、データフレームのヘッダー(列名)は1行しか扱えない。そのため、Excel上でヘッダーが複数行に分かれている場合は、1行にまとめる必要がある。以下のようにcolumns属性を使って新しい列名を指定することで、ヘッダー行を変更できる。
df_data.columns = ['列A', '列B', '列C',…] # 列名を指定また、ヘッダーの不要な行を削除する際は、Pandasではインデックスが0始まりであること、またPandasはもともと1行目をヘッダー行としてカウントしていることに注意が必要だ。したがって、Excelの2~5行目を削除したい場合は、Pandasでは0~3行目を削除する。
欠損値の扱い
欠損値のあるデータを削除したい場合は、欠損値になっていない行のみを抽出すればよい。以下のように否定の~を使って実現する。
df_data = df_data[~df_data['AAA'].isnull()]
空白の除去
データによっては、空白が含まれていることがある。その場合、空白を除去するために関数を作り、mapで適用する。以下は半角の空白を削除する例。(「データ の 整形」などのような文字列の半角空白を削除)
def remove_hankaku_kuhaku(x):
return str(x).replace(' ', '')
df_data['AAA']=df_data['AAA'].map(remove_hankaku_kuhaku) 文字列の分割
「東京Tokyo」などの文字を漢字と英字で分割したい場合は、isupperを使用してループで処理する関数を作成し、mapで適用すると良い。
def get_jp_name(x):
ja_name = ''
for num,i in enumerate(x):
if(i.isupper()): # 文字iが大文字(つまり英字部分が始まる)なら
ja_name = x[0:num] # その位置までの部分を日本語部分として取り出す
break;
return ja_name データの可視化
前処理が終わったら、最後にデータを可視化する。加工した列をmatplotlibやseaborn等で確認する。
例えば、データの件数をプロットする場合は以下のようにする。
sns.countplot(x=df_data['市町村カテゴリ'])
plt.show()
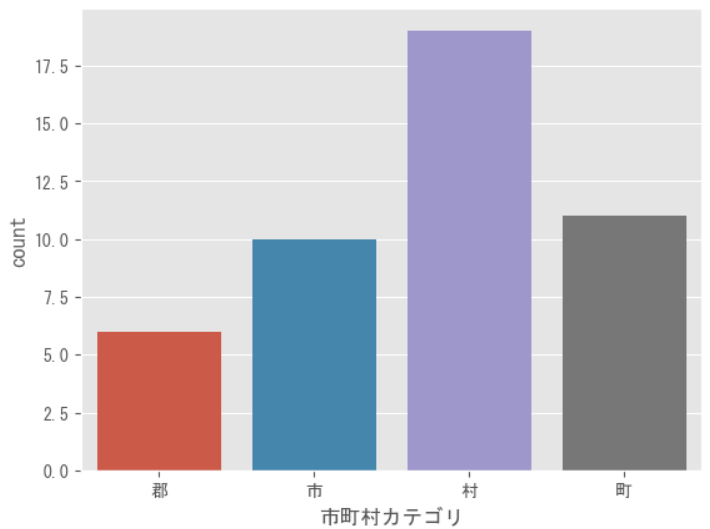
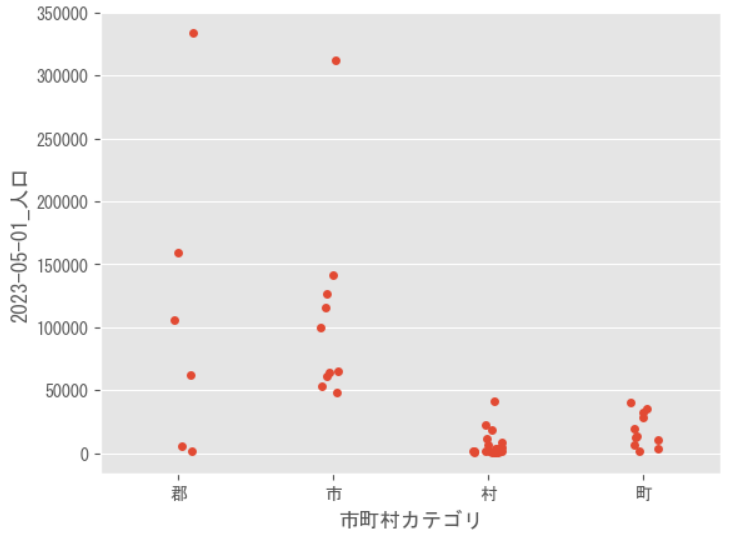
また、市町村毎の人口の分布をプロットする場合は以下のようにする。
sns.stripplot(x="市町村カテゴリ", y="2023-05-01_人口", data=df_data)
plt.show()
以上、Pandasを使ったExcelデータの読み込みと前処理についての実践的な手順を紹介しました。これらを活用して、データ分析作業をより効率的に進めてみてください。


