
機械学習モデルの開発では、モデルの訓練と評価を適切に行うためにデータの分割が必要となります。この記事では、機械学習モデルの評価に使用される主要なデータ分割手法について、具体的なコード例とともに解説します。
train_test_splitとは
train_test_splitは、Scikit-learnが提供するデータ分割関数で、機械学習モデルの訓練用データとテスト用データを簡単に分離できます。過学習を防ぎ、モデルの汎化性能を適切に評価するために不可欠な前処理ステップです。
主な用途:
- 機械学習モデルの訓練前のデータ準備
- モデル性能の客観的評価
- 過学習の検出と防止
train_test_splitの基本的な使い方
学習データとテストデータへの分割は、機械学習モデルの開発や評価において重要なステップです。分割により、モデルの訓練に使用するデータと予測性能を評価するためのデータを別々に確保することができます。
train_test_splitは、データを学習用データとテスト用データにランダムに分割するための関数です。以下はその使い方と主な引数です。
- 位置引数(可変長): 分割の対象となる配列(pandasのデータフレーム、NumPy配列、リストなど)。
- キーワード引数:
test_size: テストデータの割合または個数を指定します(0.0〜1.0の割合か、個数を指定)。train_size: 学習データの割合または個数を指定します(0.0〜1.0の割合か、個数を指定)。shuffle: Trueの場合はデータをシャッフルします。random_state: 乱数シードを指定します。
具体的な例として、糖尿病の診断データセットを使用してデータを分割してみましょう。以下のコードでは、train_test_splitを使用してデータを学習データとテストデータに分割しています。
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
# データのロード
diabetes = load_diabetes()
df_diabetes = pd.DataFrame(data=diabetes.data, columns=diabetes.feature_names)
# データの分割
train_data, test_data = train_test_split(df_diabetes, train_size=0.6, random_state=0)
# 学習データの大きさ
print(train_data.shape)
# テストデータの大きさ
print(test_data.shape)

また、説明変数と目的変数を分けて学習用データとテスト用データに分割することも可能です。以下のように、train_test_splitを使用してデータを分割しています。
# データの分割
X_train, X_test, y_train, y_test = train_test_split(df_diabetes, diabetes.target, train_size=0.6, random_state=0)
# 学習データの大きさ
print(X_train.shape)
print(y_train.shape)
# テストデータの大きさ
print(X_test.shape)
print(y_test.shape)

このように、train_test_splitを使用することで、学習データとテストデータの分割が容易に行えます。データの分割により、モデルの訓練と評価を正確かつ公平に行うことができます。
train_test_splitの引数の意味と設定例
train_test_splitの主要な引数について詳しく解説します。
| 引数 | 意味 | 設定例 | 備考 |
|---|---|---|---|
| test_size | テストデータの割合 | 0.3, 0.2 | 一般的には0.2~0.3 |
| train_size | 訓練データの割合 | 0.7, 0.8 | test_sizeと併用不可 |
| random_state | 乱数シード | 42, 0 | 再現性確保のため設定推奨 |
| shuffle | データシャッフル | True, False | デフォルトはTrue |
| stratify | 層化分割 | y | 分類問題で推奨 |
# 引数を詳細に設定した例
X_train, X_test, y_train, y_test = train_test_split(
diabetes.data,
diabetes.target,
test_size=0.2, # テストデータを20%に設定
random_state=42, # 結果の再現性を確保
shuffle=True # データをシャッフル(デフォルト)
)
pandasのsample()との使い分け
データ分割にはpandasのsample()メソッドもありますが、機械学習においてはtrain_test_splitの方が適しています。
train_test_split使用場面
- 機械学習モデルの学習・評価時
- X(説明変数)とy(目的変数)を同時に分割したい場合
- 層化分割が必要な場合
- 再現性を重視する場合
Scikit-learnでの前処理についてさらに詳しく知りたい方はデータ前処理完全ガイドをご覧ください。
pandas.sample()使用場面
- 単純なデータ抽出
- 探索的データ分析(EDA)時のサンプリング
- データフレーム全体をランダムサンプリング
# pandas方式(単純分割)
import pandas as pd
df = pd.DataFrame(diabetes.data)
df['target'] = diabetes.target
train_data = df.sample(frac=0.8, random_state=42)
test_data = df.drop(train_data.index)
print(f"訓練用データ: {train_data.shape}")
print(f"テスト用データ: {test_data.shape}")
# train_test_split方式(機械学習向け)
X_train, X_test, y_train, y_test = train_test_split(
df.drop('target', axis=1), df['target'],
test_size=0.2, random_state=42
)
print(f"X_train: {X_train.shape}, y_train: {y_train.shape}")
print(f"X_test: {X_test.shape}, y_test: {y_test.shape}")
Scikit-learnでの前処理についてさらに詳しく知りたい方はデータ前処理の基本をご覧ください。
K-分割交差検証
K-分割交差検証(K-Fold Cross-Validation)は、データ分析手法の精度を評価するための手法であり、データを複数回にわたって分割し、モデルの訓練と評価を行います。以下にK-Foldの概要図を示します。
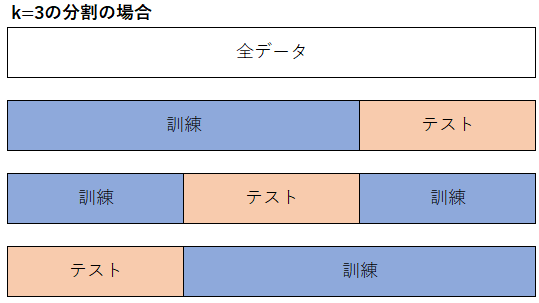
K-Foldでは、データをK個のサブセット(フォールド)に分割し、そのうちの一つをテストデータとして使用し、残りのK-1個のサブセットを学習データとして使用します。この手順をK回繰り返すことで、全てのデータが学習とテストに使用されるようになります。各回の評価結果をまとめることで、モデルの精度を評価します。
K-Foldの実装には、scikit-learnのKFoldモジュールを使用します。KFoldのインスタンスを作成する際には、以下の引数を指定します:
n_splits: データの分割数(デフォルトは5)shuffle: 連続する数字のグループ分けを行うかどうか(TrueまたはFalse)random_state: 乱数の設定
以下は、糖尿病の診断データセットを使用してK-Fold交差検証(fold=6)を行う例です。
import pandas as pd
from sklearn.model_selection import KFold
from sklearn.datasets import load_diabetes
# データのロード
diabetes = load_diabetes()
# 交差検証(fold=6)
kf = KFold(n_splits=6, shuffle=True, random_state=0)
for fold, (train_index, test_index) in enumerate(kf.split(diabetes.data, diabetes.target)):
print("Fold: {}".format(fold), "Train data size: {}".format(len(train_index)), "Test data size: {}".format(len(test_index)))

このコードでは、K-Foldのインスタンスkfを作成し、splitメソッドを使用してデータを分割しています。n_splitsを6に設定しているため、forループは6回繰り返されます。各回のループで、学習データのインデックスtrain_indexとテストデータのインデックスtest_indexが取得されます。
K-Fold交差検証を利用することで、データを効果的に使用してモデルの評価を行うことができます。データの偏りや過学習を防ぐために、K-Fold交差検証は有用な手法です。
この方法は、全てのデータが一度はテストデータとして使用されるため、データセット全体の分布を良く表現します。しかし、データが時間的な順序を持つ場合や、一部のグループが他のグループとは異なる特性を持つ場合には、適切な結果を得ることができないことがあります。
層化K-分割交差検証
層化K-分割交差検証(StratifiedKFold)は、K-分割交差検証と似ていますが、目的変数のクラスの割合を考慮したデータの分割を行う手法です。主に以下のような場合に有効です。
- 目的変数にクラスの偏りがある場合
- 目的変数のクラス数が多い場合
- クラスの割合が極端に不均衡な場合
層化K-分割交差検証では、各クラスの割合が等しくなるようにデータを分割します。これにより、各フォールドにおいて目的変数のクラスの割合を保持しながらモデルの学習と評価を行うことができます。
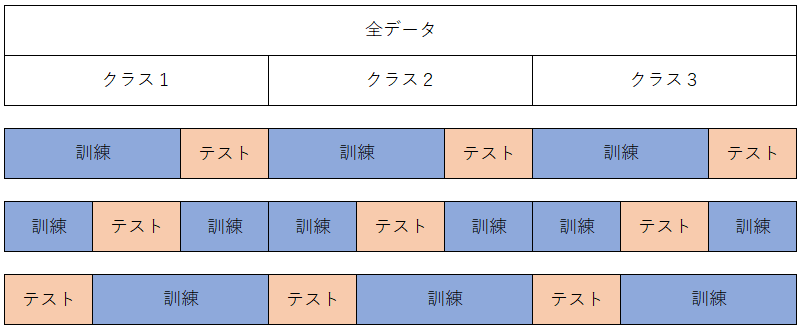
具体的な手順は以下の通りです。
- データを目的変数と説明変数に分ける。
- StratifiedKFoldのインスタンスを作成する。
- forループを用いて各フォールドにおける学習データとテストデータのインデックスを取得する。
- 各フォールドでモデルの学習と評価を行う。
以下は、ワインの分類データを用いた層化K-分割交差検証の例です。
from sklearn.model_selection import StratifiedKFold
from sklearn.datasets import load_wine
# データのロード
wine = load_wine()
df_wine = pd.DataFrame(data=wine.data, columns=wine.feature_names)
df_wine['target'] = wine.target
# 目的変数のクラス割合の確認
print(df_wine['target'].value_counts(normalize=True))
# 層化K-分割交差検証(fold=6)
kf = StratifiedKFold(n_splits=6, shuffle=True, random_state=0)
for fold, (train_index, test_index) in enumerate(kf.split(wine.data, df_wine['target'])):
print("Fold: {}".format(fold))
print(df_wine.iloc[train_index]['target'].value_counts(normalize=True))
上記のコードでは、ワインの分類データを用いて層化K-分割交差検証を行っています。まず、目的変数のクラスの割合を確認し、その後、StratifiedKFoldのインスタンスを作成し、forループを通じて各フォールドでの学習データのクラス割合を表示しています。
層化K-分割交差検証は、目的変数のクラスの偏りや不均衡な割合を考慮したデータ分割を行うため、モデルの汎化性能の評価に有用です。クラスの割合が均等でない場合に特に利用価値があります。
この方法は、クラスの不均衡が存在するデータセットに対して特に有効で、各フォールドでのクラスの割合が全体のクラスの割合と同じになるように保証します。しかし、データが時間的な順序を持つ場合や、一部のグループが他のグループとは異なる特性を持つ場合には、適切な結果を得ることができないことがあります。
グループ付き交差検証
グループ付き交差検証(GroupKFold)は、学習データとテストデータに同じグループが現れないように分割するための検証方法です。主に以下のような場合に有効です。
- ユーザIDや患者IDなどのデータに基づいてデータをグループ化したい場合
- 同じグループに属するデータが互いに依存関係を持つ場合
グループ付き交差検証では、データを分割する際にグループ情報を考慮し、学習データとテストデータの両方に同じグループが現れないようにします。これにより、データセット内の依存関係を考慮しながらモデルの汎化性能を評価することができます。
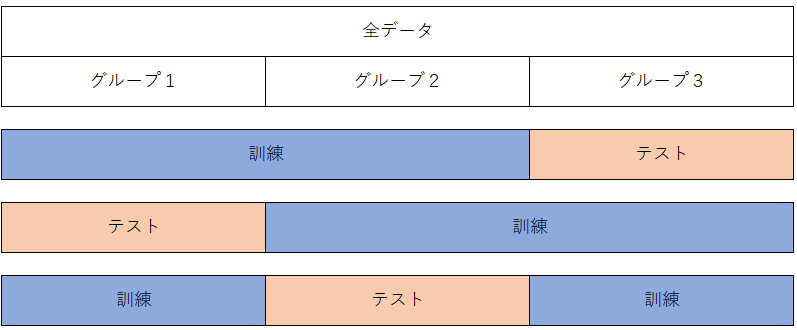
具体的な手順は以下の通りです。
- データを目的変数と説明変数、およびグループ情報に分ける。
- GroupKFoldのインスタンスを作成する。
- forループを用いて各フォールドにおける学習データとテストデータのインデックスを取得する。
- 各フォールドでモデルの学習と評価を行う。
以下は、グループ付き交差検証の例です。
from sklearn.model_selection import GroupKFold
# データの準備
df = pd.DataFrame([[1, 2], [3, 4], [5, 6], [7, 8]], columns=['col1', 'col2'])
df['target'] = [1, 2, 3, 4]
df['group'] = [0, 0, 2, 2]
# GroupKFold
kf = GroupKFold(n_splits=2)
for fold, (train_index, test_index) in enumerate(kf.split(df[['col1', 'col2']], df['target'], df['group'])):
print("Fold: {}".format(fold))
print(df.iloc[train_index]['group'].value_counts(normalize=True))

上記のコードでは、シンプルなデータに対してグループ付き交差検証を行っています。まず、データを目的変数、説明変数、およびグループ情報に分割し、GroupKFoldのインスタンスを作成します。その後、forループを通じて各フォールドでの学習データのグループの割合を表示しています。
グループ付き交差検証は、特定のグループに属するデータ同士の依存関係を考慮しながらモデルの評価を行うため、データセット内の特定のグループに関するパターンや特性を正確に評価することができます。特に、グループ間の依存関係がある場合に有効な検証方法です。
この方法は、データ内の特定のグループに対する依存性を考慮するため、特定のグループ内でのパターンを学習し過ぎることを防ぐことができます。しかし、各グループが大きく異なる特性を持つ場合や、一部のグループが他のグループと比較してサンプル数が少ない場合には、適切な結果を得ることが難しいことがあります。
時系列データ分割
時系列データ分割(TimeSeriesSplit)は、時系列データの交差検証に使用するためのKFold実装です。時系列データでは、過去のデータを使って学習し、未来のデータを使って評価するという順序が重要です。そのため、モデルの実運用を考慮してデータを分割する必要があります。
時系列データ分割の概要図を通じて、データの分割方法を確認しましょう。上記の図では、過去のデータを使って学習し、未来のデータを使って評価することを示しています。分割数が増えると、学習用データと評価用データの組み合わせが増えますが、序盤のフォールドのデータ数が減ることに注意が必要です。
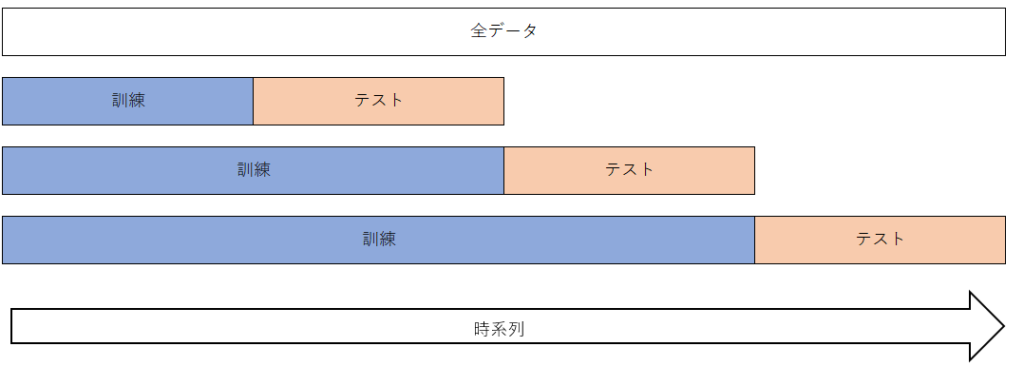
scikit-learnを使用して時系列データを分割する方法を確認しましょう。まず、TimeSeriesSplitモジュールをインポートします。TimeSeriesSplitのインスタンスを作成する際の基本的な引数は、分割数(n_splits)です。
以下は、シンプルなデータを使って時系列データ分割を行った例です。
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4], [1, 2]])
y = np.array([1, 2, 3, 4, 5, 6, 7])
tscv = TimeSeriesSplit(n_splits=6)
for train_index, test_index in tscv.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
上記のコードでは、データ(X)と目的変数(y)を用意し、TimeSeriesSplitのインスタンスを作成しています。分割数を6に指定し、forループを通じて各フォールドにおける学習データとテストデータのインデックスを表示しています。
時系列データ分割では、データの時間的な順序を考慮して学習データとテストデータを分割します。これにより、モデルの訓練と評価が正しい順序で行われ、実運用時の予測性能をより正確に評価することができます。
この方法は、時間的な順序を考慮したデータセットに対して特に有効で、過去のデータを用いて学習し、未来のデータを用いて評価するというプロセスを模倣します。しかし、データが時間的な依存性を持たない場合や、データが異なる時間範囲で異なる特性を持つ場合には、適切な結果を得ることが難しいことがあります。
よくあるエラーと対処法
エラー1: ValueError: train_size should be…
原因: train_sizeとtest_sizeの合計が1を超えている
対処法: どちらか一方のみ指定するか、合計を1以下にする
# ❌ エラーになる例
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=0.8, test_size=0.3 # 合計が1.1で超過
)
# ✅ 正しい設定
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3 # train_sizeは自動で0.7になる
)
処理が終わらない場合の対処法
原因: 大容量データの処理
対処法:
- データサイズを事前確認
- メモリ使用量の監視
- 必要に応じてサンプリング後に分割
# 大容量データの場合の対処例
print(f"データサイズ: {X.shape}")
print(f"メモリ使用量確認: {X.nbytes / 1024**2:.2f} MB")
# 必要に応じて事前サンプリング
if X.shape[0] > 100000: # 10万行を超える場合
sample_indices = np.random.choice(X.shape[0], 50000, replace=False)
X_sample = X[sample_indices]
y_sample = y[sample_indices]
X_train, X_test, y_train, y_test = train_test_split(
X_sample, y_sample, test_size=0.2, random_state=42
)
まとめ
train_test_splitは機械学習において最も基本的で重要なデータ分割手法です。適切なパラメータ設定により、モデルの性能を正確に評価できます。
重要なポイント:
- test_sizeは一般的に0.2~0.3に設定
- random_stateで結果の再現性を確保
- 分類問題では層化分割(stratify)を活用
- 時系列データではTimeSeriesSplitを使用
データの特性に応じて適切な分割手法を選択し、信頼性の高い機械学習モデルを構築しましょう。


