
PythonのライブラリであるScikit-learnは、機械学習の実装を簡単に行うことができる強力なツールです。この記事では、Scikit-learnを使用して教師あり学習を実装する方法をステップバイステップで解説します。
scikit-learnを使用した線形回帰の実装方法
scikit-learnに実装されている線形回帰の使用方法について説明します。線形回帰はsklearn.linear_modelの中からLinearRegressionというモジュールをインポートします。
単回帰分析の実装
まずは単回帰の実装です。ここでは糖尿病の診断データのデータセットを使用します。
# ライブラリのインポート
import pandas as pd
from sklearn.datasets import load_diabetes
# データのロード
diabetes = load_diabetes()
df_diabetes = pd.DataFrame(data=diabetes.data,columns=diabetes.feature_names)
df_diabetes['target'] = diabetes.target
目的変数をtarget、説明変数をbmi(肥満度を表す指標)として単回帰分析を行います。まずLinearRegressionのクラスを読み込み、インスタンス化を行います。
# クラスを読み込み
from sklearn.linear_model import LinearRegression
clf = LinearRegression()
作成したインスタンスにデータを学習させるために、説明変数(X)のデータと目的変数(Y)のデータを用意します。ここで、.reshape(-1, 1)を用いて次元数を1から2に変更しています。これは、scikit-learnの多くのアルゴリズムが2次元配列を入力として期待するためです。
# bmi(肥満度を表す指標)
X = df_diabetes['bmi'].values.reshape(-1, 1)
# 目的変数target
Y = df_diabetes['target'].values
reshape(-1, 1)という記述は、元の配列を2次元配列に変形することを指示しています。ここで、-1は「適切な数値に自動的に調整する」という意味を持ちます。つまり、reshape(-1, 1)は「元の配列の要素数を保ったまま、列数が1の2次元配列に変形する」という操作を行います。
たとえば、元の配列が [1, 2, 3, 4, 5] のような1次元配列だった場合、reshape(-1, 1)を適用すると以下のような2次元配列に変形されます。
[[1],
[2],
[3],
[4],
[5]]
このデータを、作成したインスタンスに学習させます。学習時は.fit()を用います。
# 予測モデルを作成
clf.fit(X, Y)
学習したモデル.coef_とすることで回帰係数、学習したモデル.intercept_とすることで切片を確認することができます。
# 回帰係数
print(clf.coef_)
# 切片
print(clf.intercept_)

重回帰分析の実装
次は重回帰です。まず、同様に糖尿病の診断データのデータセットを読み込みます。
# ライブラリのインポート
import pandas as pd
from sklearn.datasets import load_diabetes
# データのロード
diabetes = load_diabetes()
df_diabetes = pd.DataFrame(data=diabetes.data,columns=diabetes.feature_names)
df_diabetes['target'] = diabetes.target
目的変数をtarget、説明変数をtarget以外として重回帰分析を行います。まず単回帰分析と同様にLinearRegressionのクラスを読み込み、インスタンス化を行います。説明変数のカラム名はdiabetes.feature_namesから取得します。
# インスタンス作成
clf = LinearRegression()
# 説明変数
X = df_diabetes[diabetes.feature_names].values
# 目的変数target
Y = df_diabetes['target'].values
データの準備ができたらあとfitさせるだけです。偏回帰係数と切片も表示してみます。
# 予測モデルを作成
clf.fit(X, Y)
# 回帰係数
print(clf.coef_)
# 切片
print(clf.intercept_)

以上が重回帰分析の実施方法です。得られた回帰係数から、各説明変数が目的変数にどの程度影響を与えているかを確認することができます。
scikit-learnを使用したロジスティック回帰の実装方法
ロジスティック回帰は分類問題を解くための一つの手法で、scikit-learnにはこのロジスティック回帰を実装するためのモジュールが含まれています。ここでは、その使用方法について詳しく見ていきましょう。
まず、ロジスティック回帰を使用するためには、scikit-learn.linear_modelからLogisticRegressionというモジュールをインポートします。次に、LogisticRegressionのインスタンスを作成します。
ロジスティック回帰を用いた2値分類の実装
具体的な2値分類問題を解く手順を説明します。ここでは、乳がんのデータセットを用いて「悪性腫瘍(0)」か「良性腫瘍(1)」かを分類します。
まず、必要なライブラリをインポートし、データセットをロードします。
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
breast = load_breast_cancer()
df_breast = pd.DataFrame(data=breast.data,columns=breast.feature_names)
df_breast['target'] = breast.target
次に、目的変数のクラス比率を確認します。
df_breast['target'].value_counts()

これでデータセットの準備が整いました。次に、データを学習用とテスト用に分割し、モデルを作成します。ここでは、solverパラメータをliblinearに設定しています。これは比較的小さいデータセットに対して適しているソルバーです。
from sklearn.model_selection import train_test_split
clf = LogisticRegression(solver='liblinear')
X = df_breast[breast.feature_names].values
Y = df_breast['target'].values
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2)
選択できるソルバーの種類について捕捉します。
liblinear:上述の通り、小規模なデータセットに適しています。一対他(one-vs-rest)のアプローチを用いて多クラス問題を解くため、多クラス問題に対しては他のソルバーよりも効率が悪い場合があります。newton-cg、lbfgs、sag:これらのソルバーは大規模なデータセットに対して適しており、多クラス問題を解く際には真の多クラスロジスティック回帰を使用します。ただし、これらのソルバーは収束するまでに時間がかかることがあります。saga:sagソルバーの改良版で、大規模なデータセットに対して適しています。また、L1正則化とElastic-Net正則化をサポートしています。
データの準備が整ったら、モデルを学習させ、テストデータに対して予測を行います。
clf.fit(X_train, y_train)
clf.predict(X_test)
また、.predict_proba()を使用すると、各クラスに属する確率を算出することができます。
clf.predict_proba(X_test)

最後に、モデルの精度を計算します。ここではsklearn.metrics.accuracy_scoreを使用します。
from sklearn.metrics import accuracy_score
accuracy_score(y_test,clf.predict(X_test))
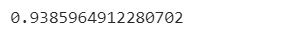
以上でロジスティック回帰を用いた2値分類の一連の流れを学びました。パラメータを変更したり、データの分割比率を変更して、どのように結果が変わるか試してみると良いと思います。
scikit-learnを使用したランダムフォレストの実装方法
ランダムフォレストは決定木を基にしたアンサンブル学習の一つで、scikit-learnにはこのランダムフォレストを実装するためのモジュールが含まれており、その使用方法について詳しく見ていきます。
ランダムフォレストのモジュールにはこれまでに上でご紹介したモデルと同様のメソッドも存在しますが、独自のメソッドも存在します。その1つがfeature_importances_で、学習した際にどの特徴量が効いたかを定量的に算出することが可能となります。
ランダムフォレストを使用した分類の実装
それではランダムフォレストを使用して具体的な分類問題を解いてみます。ここでは、乳がんのデータセットを用いて「悪性腫瘍(0)」か「良性腫瘍(1)」かを分類します。
まず、必要なライブラリをインポートし、データセットをロードします。
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
breast = load_breast_cancer()
df_breast = pd.DataFrame(data=breast.data,columns=breast.feature_names)
df_breast['target'] = breast.target次に、データを学習用とテスト用に分割し、モデルを作成します。ここでは、RandomForestClassifierのインスタンスを作成し、デフォルトのパラメータ設定を使用します。
from sklearn.model_selection import train_test_split
clf = RandomForestClassifier()
X = df_breast[breast.feature_names].values
Y = df_breast['target'].values
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2)データの準備が整ったらモデルを学習させ、テストデータに対して予測を行います。
clf.fit(X_train, y_train)最後に、モデルの精度を計算します。ここではsklearn.metrics.accuracy_scoreを使用します。
from sklearn.metrics
import accuracy_score
print(accuracy_score(y_test,clf.predict(X_test)))さらに、ランダムフォレストの特徴である特徴量重要度を確認します。これにより、モデルがどの特徴量を重視しているのかを定量的に判断することができます。
feature_importance = pd.DataFrame({'feature':breast.feature_names,'importances':clf.feature_importances_}).sort_values(by="importances", ascending=False)
print(feature_importance.head())
以上でランダムフォレストを用いた分類の一連の流れを学びました。乱数を未設定としているため、学習のたびに数値や特徴量重要度に違いが生まれます。ぜひソースコードを実行しながら精度などを確認してみてください。
ランダムフォレストを使用した回帰分析の実装
次にランダムフォレストを用いて糖尿病の診断データに対する回帰分析を行います。
まず、必要なライブラリをインポートし、糖尿病の診断データセットをロードします。そして、ランダムフォレストの回帰モデルを作成し、データを訓練データとテストデータに分割します。最後に、訓練データを用いてモデルを訓練します。
# ライブラリのインポート
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# データのロード
diabetes = load_diabetes()
df_diabetes = pd.DataFrame(data=diabetes.data,columns=diabetes.feature_names)
df_diabetes['target'] = diabetes.target
# インスタンス作成
clf = RandomForestRegressor(random_state=0)
# 説明変数
X = df_diabetes[diabetes.feature_names].values
# 目的変数target
Y = df_diabetes['target'].values
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2,random_state=0)
# 予測モデルを作成
clf.fit(X_train, y_train)次に、ランダムフォレストの特徴量重要度を確認します。ここではさらに可視化することでどの特徴量が予測に重要な役割を果たしているかをより視覚的に理解することができます。
# ライブラリのインポート
import matplotlib.pyplot as plt
import seaborn as sns
# 特徴量重要度
feature_importance = pd.DataFrame({'feature':diabetes.feature_names,'importances':clf.feature_importances_}).sort_values(by="importances", ascending=False)
# 可視化
sns.barplot(x="importances", y="feature", data=feature_importance.head())
plt.show()
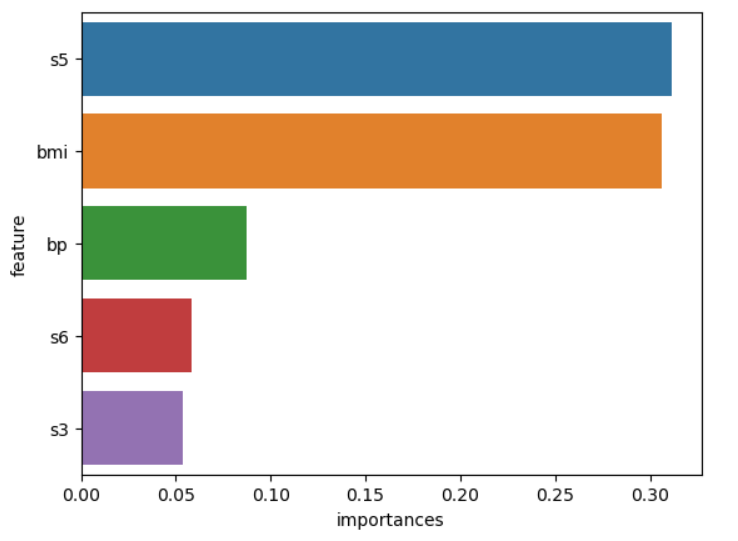
以上が、ランダムフォレストを用いた回帰分析の基本的な手順です。ランダムフォレストは、その予測精度の高さと特徴量重要度を容易に取得できる点から、多くのデータ分析や機械学習タスクで広く利用されています。
scikit-learnを使用したサポートベクターマシンの実装方法
サポートベクターマシン(SVM)は、分類や回帰、異常検知などの機械学習タスクに広く使用される強力なモデルです。scikit-learnには様々なタイプのSVMが実装されています。
scikit-learnに実装されている主なSVMは以下の通りです:
- 分類問題に使用する SVM(Support Vector Classification)
- SVC(C-Support Vector Classification):標準的なソフトマージン(エラーを許容する)SVM
- LinearSVC(Linear Support Vector Classification):カーネルが線形カーネルの場合に特化したSVM
- NuSVC(Nu-Support Vector Classification):エラーを許容する表現が異なるSVM
- 回帰問題に使用する SVM(Support Vector Regression)
- SVR
- LinearSVR
- NuSVR
- 異常検知に使用する SVM
- OneClassSVM
今回は、これらの中でも最も標準的なSVMであるSVCを例に学習していきます。SVCはscikit-learn.svmからインポートできます。
サポートベクターマシン(SVM)を使用した分類の実装
サポートベクターマシン(SVM)を使って具体的な分類問題を解いてみます。ここでは、乳がんのデータセットを用いて「悪性腫瘍(0)」か「良性腫瘍(1)」かを分類します。
まず、必要なライブラリをインポートし、データセットをロードします。
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
breast = load_breast_cancer()
df_breast = pd.DataFrame(data=breast.data,columns=breast.feature_names)
df_breast['target'] = breast.target次に、データを学習用とテスト用に分割し、モデルを作成します。ここでは、SVCのインスタンスを作成し、デフォルトのパラメータ設定を使用します。
from sklearn.model_selection import train_test_split
# SVMのインスタンスを作成します。ここではrandom_stateを0に設定しています。
# random_stateは乱数のシード値を設定するパラメータで、これにより同じ結果を再現することが可能になります。
clf = SVC(random_state=0)
X = df_breast[breast.feature_names].values
Y = df_breast['target'].values
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2,random_state=0)データの準備が整ったら、モデルを学習させ、テストデータに対して予測を行います。
clf.fit(X_train, y_train)最後に、モデルの精度を計算します。ここではsklearn.metrics.accuracy_scoreを使用します。<br>
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test,clf.predict(X_test)))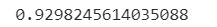
以上でサポートベクターマシンを用いた分類の一連の流れを学びました。乱数を未設定としているため、学習を実行するごとに数値に違いが生まれます。ぜひソースコードを実行しながら精度などを確認してみてください。
scikit-learnを使用したK近傍法の実装方法
K近傍法(K-Nearest Neighbors、K-NN)は、教師あり学習の一種で、分類問題や回帰問題に使用されます。scikit-learnライブラリでは、分類問題の場合はKNeighborsClassifier、回帰問題の場合はKNeighborsRegressorというモジュールが提供されています。
K近傍法の基本的な考え方は、未知のデータが与えられたとき、そのデータがどのクラスに属するかを決定するために、既知のデータ(学習データ)の中から最も近いk個のデータを見つけ、それらのデータの多数決によって未知のデータのクラスを決定します。
K近傍法を使用した分類の実装
K近傍法は、その名の通り未知のデータ点のクラスを決定する際にそのデータ点から最も近いk個の既知のデータ点を見て、それらの多数決によってクラスを決定する方法です。今回は、このK近傍法を用いて乳がんのデータセットを分類してみます。
まずは、必要なライブラリをインポートします。ここではpandas、numpy、そしてscikit-learnから必要なモジュールをインポートします。
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score次に、乳がんのデータセットをロードします。このデータセットはscikit-learnのload_breast_cancer関数を用いてロードすることができます。
breast = load_breast_cancer()
df_breast = pd.DataFrame(data=breast.data,columns=breast.feature_names)
df_breast['target'] = breast.target次に、K近傍法のインスタンスを作成します。ここでは、近傍の数(n_neighbors)を3としています。
clf = KNeighborsClassifier(n_neighbors=3)次に、説明変数と目的変数を設定します。
X = df_breast[breast.feature_names].values
Y = df_breast['target'].valuesそして、データを学習用とテスト用に分割します。ここでは、テストデータの割合を全体の20%(0.2)としています。
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2,random_state=0)データの準備が整ったら、モデルを学習させます。
clf.fit(X_train, y_train)最後に、テストデータを用いて予測を行い、その精度を計算します。
accuracy_score(y_test,clf.predict(X_test))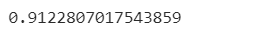
精度は約0.912となりました。このように、K近傍法は非常にシンプルながらも、適切なパラメータ設定により高い精度を達成することが可能です。特に、近傍の数(n_neighbors)を変えることで、モデルの精度がどのように変わるかを確認してみると良いでしょう。
K近傍法を使用した回帰の実装
K近傍法は分類だけでなく、回帰問題にも適用することができます。今回は、糖尿病の診断データを用いて、K近傍法を使った回帰モデルの作成を行います。
まずは、必要なライブラリをインポートします。
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.neighbors import KNeighborsRegressor
from sklearn.model_selection import train_test_split次に、糖尿病の診断データセットをロードします。
diabetes = load_diabetes()
df_diabetes = pd.DataFrame(data=diabetes.data,columns=diabetes.feature_names)
df_diabetes['target'] = diabetes.target次に、K近傍法の回帰モデルのインスタンスを作成します。
clf = KNeighborsRegressor()次に、説明変数と目的変数を設定します。
X = df_diabetes[diabetes.feature_names].values
Y = df_diabetes['target'].valuesそして、データを学習用とテスト用に分割します。
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2,random_state=0)データの準備が整ったら、モデルを学習させます。
clf.fit(X_train, y_train)作成したモデルの詳細は、作成したインスタンスを表示することで確認することができます。
print(clf)
以上で、K近傍法を使った回帰モデルの作成が完了しました。今回説明したアルゴリズムを使って、様々なデータに対して予測モデルを作成してみてください。
この記事では、Scikit-learnを使用して、線形回帰、ロジスティック回帰、ランダムフォレスト、SVM、K近傍法など、さまざまな教師あり学習の実装方法について説明しました。これらの手法は、様々なデータ分析や機械学習タスクに応用することができます。各手法の特性や適用範囲を理解し、適切な手法を選択して利用することが、データ分析の成功に繋がります。ぜひ、この記事を参考に、ご自身のデータ分析プロジェクトに活用してみてください。


