

scikit-learnはPythonの機械学習ライブラリの一つで、その中にはDataset-APIという便利な機能が含まれています。このAPIを活用することで、機械学習アルゴリズムを試験的に使ってみる際に必要なテストデータセットを簡単に取得することが可能となります。
Dataset-APIの提供するデータセットの種類
scikit-learnのDataset-APIでは、主に2種類のデータセットを提供しています。
- トイ・データセット(Toy dataset):ダウンロードが不要で、簡易的な検証に利用できるデータセットです。
- 実世界データセット(Real world dataset):ダウンロードが必要で、サイズが大きい実世界のデータセットです。
トイ・データセットの例
scikit-learnが提供しているトイ・データセットの一部を以下に紹介します。
- アヤメの計測データ(分類問題用):load_iris
- 糖尿病の診断データ(回帰問題用):load_diabetes
- 数字の手書き文字(分類問題用):load_digits
- 生理学的特徴と運動能力の関係(回帰問題用):load_linnerud
- ワインの科学的特徴(分類問題用):load_wine
- 乳がんの診断データ(分類問題用):load_breast_cancer
これらのデータセットは、分類問題や回帰問題など、機械学習のさまざまなタスクに対応しています。
実世界データセット一覧
また、scikit-learnが提供している実世界データセットの一部を以下に紹介します。
- 顔画像(分類問題用):fetch_olivetti_faces
- トピック別ニュース記事(分類問題用):fetch_20newsgroups
- トピック別のニュース記事(特徴抽出済、分類問題用):fetch_20newsgroups_vectorized
- 有名人の顔写真(分類問題用):fetch_lfw_people
- 有名人の顔写真(ペア版、分類問題用):fetch_lfw_pairs
- 木の種類(分類問題用):fetch_covtype
- カテゴリ別のニュース(分類問題用):fetch_rcv1
- ネットワークの侵入検知(分類問題用):fetch_kddcup99
- カリフォルニアの住宅価格(回帰問題用):fetch_california_housing
これらの実世界データセットは、画像や自然言語を用いた分類問題など、より複雑なタスクに対応しています。ただし、データのサイズが大きいため、頻繁に使用することは少ないでしょう。
データセットの利用方法:「生理学的特徴と運動能力の関係」データセットの例
今回は、その中から「生理学的特徴と運動能力の関係」データセットを取り出し、データの概要を確認してみます。
まずは、scikit-learnからload_linnerudモジュールをインポートし、そのインスタンスをlinnerudという変数に格納します。
from sklearn.datasets import load_linnerud
linnerud = load_linnerud()
このlinnerud変数には、「生理学的特徴と運動能力の関係」データセットに関する情報が格納されています。具体的には、説明変数のデータ値(linnerud.data)、説明変数のカラム名(linnerud.feature_names)、目的変数のデータ値(linnerud.target)を取り出すことができます。
しかし、これらのデータはnumpy.ndarray形式で格納されているため、そのままではデータの概要を把握しにくいです。そこで、pandasのDataFrame形式に変換することで、データをより見やすくします。
import pandas as pd
df_linnerud = pd.DataFrame(data=linnerud.data, columns=linnerud.feature_names)
これで、説明変数のデータがDataFrameとして使用できます。ただし、このDataFrameには目的変数(運動能力)が含まれていません。そこで、新たにChins、Situps、Jumpsというカラムを作成し、そこにlinnerud.targetのデータを代入します。
df_linnerud['Chins'] = linnerud.target[:, 0]
df_linnerud['Situps'] = linnerud.target[:, 1]
df_linnerud['Jumps'] = linnerud.target[:, 2]
以上の手順で、scikit-learnから「生理学的特徴と運動能力の関係」データセットを読み込み、データの概要を確認することができました。
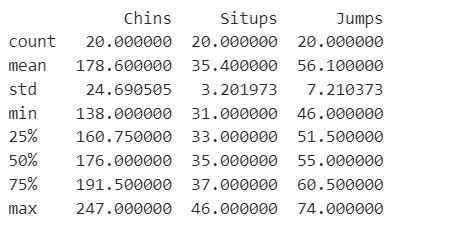
では簡単にデータの中身を見てみます。DataFrame形式のデータの基本統計量は.describe()にて確認できます。
print(df_linnerud.describe())
以上、scikit-learnのDataset-APIを活用したデータセットの取得と利用方法について解説しました。これらのデータセットを用いて、機械学習モデルの作成と評価を手軽に行ってみてください。


