
はじめに
機械学習の世界では、データの前処理は成功の鍵となる重要なステップです。前処理が適切に行われていないと、どんなに優れたアルゴリズムを用いても、モデルの性能は大きく低下します。今回の記事では、Pythonのライブラリであるscikit-learnを用いて、データ前処理の基本的な手法を解説します。具体的には、データの標準化、正規化、ラベルエンコード、ワンホットエンコードについて記載します。
データの標準化:平均と標準偏差の調整
データの標準化とは、データの平均を0に、標準偏差を1に調整するプロセスのことを指します。これは、特にニューラルネットワークのようなアルゴリズムで重要となります。なぜなら、ニューラルネットワークは入力データのスケールに敏感であり、標準化されていないデータを用いると学習が不安定になるか、または全く学習が進まない可能性があるからです。
具体的な実践例として、ワインのデータセットを用いた標準化のプロセスを紹介します。このプロセスでは、scikit-learnのStandardScalerを用いて、データセットの各特徴量の平均が0、標準偏差が1になるように変換します。
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.preprocessing import StandardScaler
wine = load_wine()
df_wine = pd.DataFrame(data=wine.data,columns=wine.feature_names)
df_wine['target'] = wine.target
sc = StandardScaler()
sc.fit(df_wine)
df_wine_sc = pd.DataFrame(sc.transform(df_wine), columns=df_wine.columns)
display(df_wine_sc.describe().round(2))
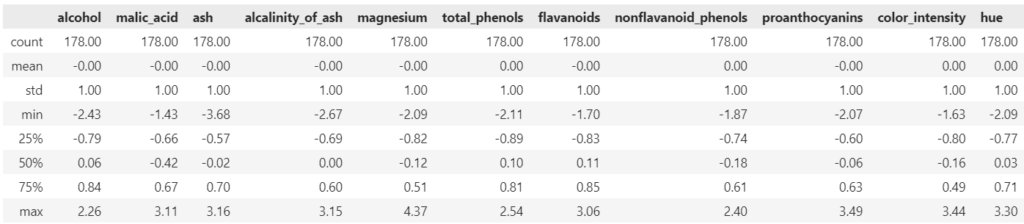
標準化後のデータの平均(mean)が0、標準偏差(std)が1(あるいはそれに近い値)になっていることを確認することで、標準化が正しく行われたことを確認できます。
データの正規化:特徴量の範囲調整
データの正規化とは、特徴量の値の範囲を一定の範囲に収めるスケーリング手法のことを指します。データを[0, 1]または[-1, 1]の範囲に収めることが一般的です。これは、特徴量の範囲が大きく異なる場合や、特徴量が一様分布を持つ場合に特に有効です。
具体的な実践例として、ワインのデータセットを用いた正規化のプロセスを紹介します。このプロセスでは、scikit-learnのMinMaxScalerを用いて、データセットの各特徴量の最小値が-1、最大値が1になるように変換します。
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.preprocessing import MinMaxScaler
wine = load_wine()
df_wine = pd.DataFrame(data=wine.data,columns=wine.feature_names)
df_wine['target'] = wine.target
ms = MinMaxScaler((-<span class="hljs-number">1</span>,<span class="hljs-number">1</span>))
ms.fit(df_wine)
df_wine_ms = pd.DataFrame(ms.transform(df_wine), columns=df_wine.columns)
display(df_wine_ms.describe().round(2))
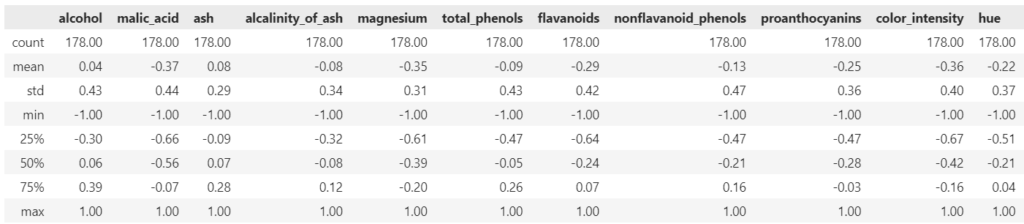
正規化後のデータの最小値(min)が-1、最大値(max)が1になっていることを確認することで、正規化が正しく行われたことを確認します。
ラベルエンコード:カテゴリ変数を数値に変換
ラベルエンコードとは、カテゴリ変数を数値に変換する手法のことを指します。これにより、性別や血液型などのカテゴリ変数を機械学習モデルに入力する際に、これらの変数を何らかの数値に置き換えることが可能となります。しかしカテゴリの数が多い場合、手動でのマッピングは大変な作業になります。そこで、scikit-learnのLabelEncoderを使用することで、この作業を効率化することができます。
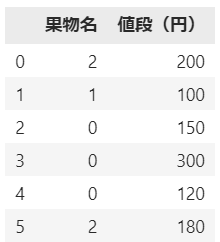
具体的な使用例として、果物名と値段を含むテストデータを用いたラベルエンコードのプロセスを紹介します。このプロセスでは、LabelEncoderを用いて、’果物名’カラムの各カテゴリが一意の整数に変換されます。
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame({
'果物名': ['リンゴ', 'バナナ', 'オレンジ', 'オレンジ', 'オレンジ', 'リンゴ'],
'値段(円)': ['200', '100', '150', '300', '120', '180'],
})
le = LabelEncoder()
le = le.fit(df['果物名'])
df['果物名'] = le.transform(df['果物名'])
df
ワンホットエンコード:カテゴリ変数をベクトルに変換
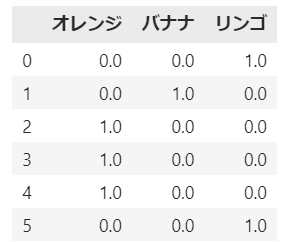
ワンホットエンコードとは、カテゴリ変数をワンホットエンコードする手法のことを指します。これは、例えば「リンゴ、バナナ、オレンジ」などのカテゴリ変数を扱いたい場合に有用です。リンゴ→(1,0,0)、バナナ→(0,1,0)、オレンジ→(0,0,1)のように、それぞれを多次元のベクトルで表現する方法をワンホット表現と呼びます。これにより、変数の全ての値を平等に扱うことが可能となります。
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
df = pd.DataFrame({
'果物名': ['リンゴ', 'バナナ', 'オレンジ', 'オレンジ', 'オレンジ', 'リンゴ']
})
enc = OneHotEncoder(sparse=False)
df = pd.DataFrame(enc.fit_transform(df),columns=enc.categories_)
df
以上、scikit-learnを用いたデータ前処理の基本的な手法を詳しく解説しました。これらの手法を理解し適切に活用することで、機械学習モデルの精度を向上させることが可能となります。


