
今日はPythonを使ったウェブスクレイピングデータの前処理についてのまとめです。
例として警視庁の公式ウェブサイトから反則行為のデータを取得し、その前処理を行う方法について手順を追っていきます。
Pythonとウェブスクレイピング
Pythonでウェブスクレイピングを行う際、主に2つのライブラリが活躍。それが「requests」と「BeautifulSoup」の2つ。
- requests:ウェブページを取得する際に使用。
- BeautifulSoup:取得したウェブページを解析し、タグの検索やデータの整形を行う。
スクレイピング対象のウェブサイト
今回のスクレイピング対象は、警視庁に掲載されている反則行為の一覧。放置・駐停車に関するもの以外を取得。
URLは以下の通り。
https://www.keishicho.metro.tokyo.lg.jp/menkyo/torishimari/tetsuzuki/hansoku.html
requestsでURL取得
まずはrequestsを使って、上記のURLからウェブページを取得。
# ライブラリのインポート
import requests
url = 'https://www.keishicho.metro.tokyo.lg.jp/menkyo/torishimari/tetsuzuki/hansoku.html'
r = requests.get(url)BeautifulSoupで整形
次にBeautifulSoupを使って、取得したウェブページを整形。
# ライブラリのインポート
from bs4 import BeautifulSoup
# HTMLの整形
soup = BeautifulSoup(r.content, 'html.parser')
# bodyタグの出力
print(soup.body)
<出力結果>
タグ検索
BeautifulSoupには、特定のタグを検索する機能がある。
- soup.find:一件のみ検索。
- soup.find_all:全件検索。返り値はリスト。
# データの整形
soup = BeautifulSoup(r.content, 'html.parser')
# タグ名1件検索
print(soup.find('th'))
# タグ名全検索
print(soup.find_all('th'))
# tdタグデータ数取得
print(len(soup.find_all('td')))
<出力結果>

find_allにてさらに条件を加えて取得
find_allだけだと例えば<a>で始まるアンカータグを全部拾ってきて都合が悪い。そこでULRなどの属性や、id、classなどを指定して取得する。
以下適当なURLを作成した上でのコード例。classの場合にはアンダースコア(_)を付ける必要があることに注意。
# ライブラリのインポート
from bs4 import BeautifulSoup
# 対象のHTML
html = '''\
<a class="test1" id="link1" href="https://tai.jp/"><span>たいのウェブページへようこそ</span></a>\
<a class="test2" id="link1"><span>項目1</span></a>\
<a class="test3" id="link2"><span>項目2</span></a>\
<a class="test3" id="link3"><span>項目3</span></a>\
'''
# データの整形
soup = BeautifulSoup(html, 'html.parser')
# 属性検索
print(soup.find_all('a',href="https://tai.jp/"))
# id検索
print(soup.find_all('a',id="link1"))
# class検索
print(soup.find_all('a',class_="test2"))
<出力結果>
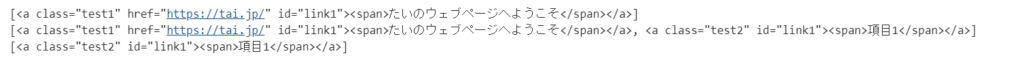
正規表現を使って取得
正規表現を使ってデータを取得することも可能。以下のコードはtで始まるタグ(titleタグやtrタグ、tdタグなど)を取得。
# ライブラリのインポート
from bs4 import BeautifulSoup
# データの整形
soup = BeautifulSoup(r.content, 'html.parser')
# 正規表現を使ってデータ検索
import re
soup.find_all(re.compile('^t'))<出力結果>

ヘッダーデータのスクレイピング
取得したいデータを持つ場所をHTMLから確認→タグ情報検索を利用してデータを抜き出すという流れ。findやfind_allの結果は連続使用できるので、以下のコードのようにカラム名を取得する場合にはテーブル→レコード→ヘッダーと狭めていく。
# データの整形
soup = BeautifulSoup(r.content, 'html.parser')
# 情報格納の受け皿を用意
head_cols =[]
# 要素から`.text`を用いて文字列を取得し、受け皿に格納
for tag in (soup.find('table').find_all("tr")[1].find_all('th')):
head_cols.append(tag.text)
# 受け皿を表示
print(head_cols)<出力結果>

表データのスクレイピング
改めて元データを見ると「速度超過」のような結合列が存在する。
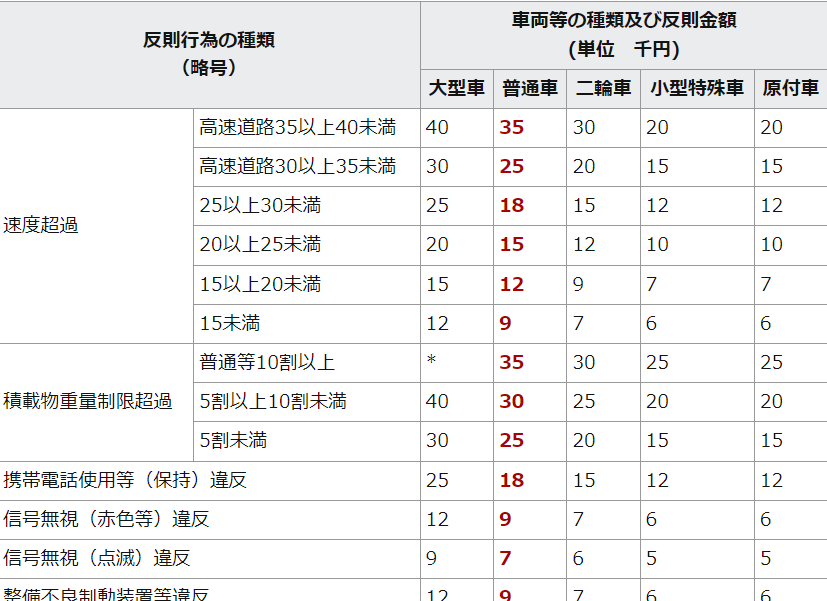
カラムに結合があるとずれが発生するので、テクニックの1つとして後ろの列から順に取得するようなことを行う。
取得したデータはデータフレームに格納する。
# ライブラリのインポート
import pandas as pd # データの整形
soup = BeautifulSoup(r.content, 'html.parser')
# 表データの抽出
# 全データを保持する用の受け皿を用意
list1 = []
for record in (soup.find('table').find_all('tr')[2:]):
# 各レコードごとのデータを保持する用の受け皿を用意
list2 = []
for yoso in (record.find_all('td')[::-1]):
# 各セルの文字列を格納
list2.append(yoso.text)
# 各レコードごとのリストを格納
list1.append(list2)
# DataFrame形式に変更
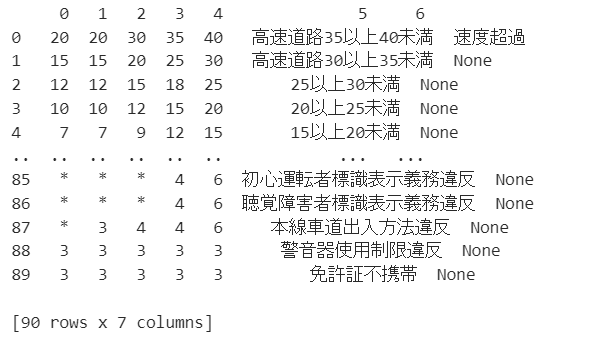
df_data = pd.DataFrame(list1)
print(df_data)<出力結果>
最後に整形する
元のテーブルデータをデータフレームに合致させるために整形させていく。
# データフレームのカラムを逆順に並び替える
df_data = df_data[df_data.columns[::-1]]
# 欠損のあるカラム「6」の整形
df_data.loc[(df_data.index>=0) & (df_data.index<=5),6] = '速度超過'
df_data.loc[(df_data.index>=6) & (df_data.index<=8),6] = '積載物重量制限超過'
# カラム「6」とカラム「5」の文字列を結合し、カラム「5」に格納する
# もしカラム「6」の値が欠損している場合は、空文字列で置換する
df_data[5] = df_data[6].str.cat(df_data[5], na_rep='')
# 不要となったカラム「6」を削除
df_data = df_data.drop(6,axis=1)
# カラム名を新しいリストで上書きする
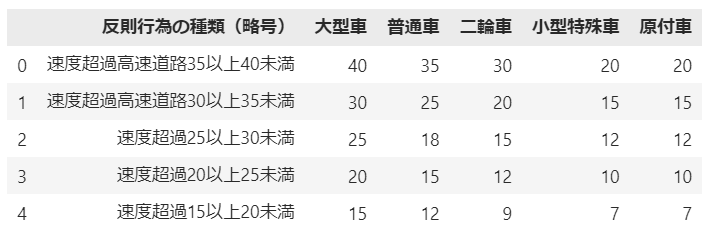
df_data.columns = ['反則行為の種類(略号)', '大型車', '普通車', '二輪車', '小型特殊車', '原付車']
# 先頭5行の表示
df_data.head()
以上、Pythonを使ったウェブスクレイピングとデータの前処理についてまとめました。この方法を使えば、ウェブサイトから自由にデータを取得し、整形することが可能となります。皆さんもぜひ試してみてください。


