
機械学習モデルの性能を最大化するために欠かせないのがGridSearchCV(グリッドサーチ)を使ったハイパーパラメータの最適化です。
本記事では、PythonのsciKit-learnライブラリを使って、GridSearchCVの使い方を初心者でも理解できるよう実装例とともに詳しく解説します。決定木からLightGBMまで、実際に動くコードで学んでいきましょう。
この記事で学べること:
- GridSearchCVの基本的な使い方
- パラメータ探索の実装方法
- 結果の可視化と解釈
- 複数パラメータでの最適化
- よくあるエラーの対処法
グリッドサーチとは?基本概念と目的
ハイパーパラメータチューニングの重要性
機械学習において、ハイパーパラメータはモデルの性能を大きく左右する重要な要素です。例えば、決定木の最大深度やランダムフォレストの木の数など、これらの値を適切に設定することで、モデルの予測精度を大幅に向上させることができます。
グリッドサーチとは、指定したハイパーパラメータの範囲内で全ての組み合わせを体系的に試し、最も評価指標が高くなるパラメータの組み合わせを見つける手法です。
グリッドサーチとランダムサーチの違い
ハイパーパラメータ最適化には複数の手法があります。主要な手法を比較してみましょう:
| 項目 | グリッドサーチ | ランダムサーチ | ベイジアン最適化 |
|---|---|---|---|
| 探索方法 | 全組み合わせを体系的に探索 | ランダムに抽出して探索 | 確率的モデルで効率的に探索 |
| 計算時間 | 長い(全探索のため) | 中程度 | 比較的短い |
| 精度 | 高い(見落としなし) | 中程度 | 高い |
| 適用場面 | パラメータ数が少ない場合 | 予備探索・時間制約がある場合 | 実用的な最適化 |
| メリット | 確実に最適解を発見 | 計算効率が良い | 効率的で実用的 |
| デメリット | 計算コストが高い | 最適解を見逃す可能性 | 実装がやや複雑 |
グリッドサーチを選ぶべき場面:
- パラメータ数が比較的少ない(2-3個程度)
- 計算時間に余裕がある
- 確実に最適解を見つけたい
GridSearchCVの使い方|基本的な実装手順
必要なライブラリのインポートと設定
まず、GridSearchCVを使用するために必要なライブラリをインポートします。
# 必要なライブラリのインポート
from sklearn.tree import DecisionTreeClassifier as DT
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import roc_auc_score
import matplotlib.pyplot as plt
import numpy as np
# 決定木モデルの準備
# random_state=0を指定して、結果の再現性を保証
tree = DT(random_state=0)GridSearchCVは、scikit-learnのmodel_selectionモジュールに含まれるクラスで、指定したハイパーパラメータの全ての組み合わせについて、クロスバリデーションを用いてモデルの性能を評価することができます。
パラメータ探索範囲の指定方法
探索したいパラメータとその範囲を辞書形式で定義します。
# 探索するパラメータの設定
# ここでは、決定木の最大深度を2から10までの範囲で探索
parameters = {"max_depth": [2, 3, 4, 5, 6, 7, 8, 9, 10]}パラメータ範囲の決め方のコツ:
- 狭すぎず広すぎない範囲を設定する
- デフォルト値を中心に前後の値を含める
- 計算時間を考慮して現実的な範囲にする
クロスバリデーションの設定
GridSearchCVのインスタンスを作成し、クロスバリデーションと評価指標を設定します。
# グリッドサーチの設定
# cv=5で5分割のクロスバリデーションを行い、評価指標はAUC
# return_train_score=Trueで、学習データに対するスコアも計算
gcv = GridSearchCV(
estimator=tree, # 使用するモデル
param_grid=parameters, # 探索するパラメータ
cv=5, # クロスバリデーションの分割数
scoring='roc_auc', # 評価指標
return_train_score=True, # 学習スコアも記録
n_jobs=-1 # 並列処理(オプション)
)主要なパラメータの説明:
cv: クロスバリデーションの分割数(通常3-10)scoring: 評価指標(’accuracy’, ‘roc_auc’, ‘f1’など)n_jobs: 並列処理数(-1で全CPUを使用)
実践例:決定木でのGridSearchCV活用
単一パラメータでの探索実行
実際にグリッドサーチを実行してみましょう。
# グリッドサーチの実行
# ここでtrain_X, train_yは事前に準備されている学習データ
gcv.fit(train_X, train_y)
print("グリッドサーチ完了!")
print(f"試行した組み合わせ数: {len(gcv.cv_results_['params'])}")結果の可視化と解釈方法
グリッドサーチの結果を可視化して、パラメータと性能の関係を理解しましょう。
# グリッドサーチの結果から、学習データとテストデータのスコアを取得
train_scores = gcv.cv_results_["mean_train_score"]
test_scores = gcv.cv_results_["mean_test_score"]
train_std = gcv.cv_results_["std_train_score"]
test_std = gcv.cv_results_["std_test_score"]
# パラメータ値のリスト
max_depths = [2, 3, 4, 5, 6, 7, 8, 9, 10]
# グラフの作成
plt.figure(figsize=(10, 6))
# 学習データのスコアをプロット(エラーバー付き)
plt.errorbar(max_depths, train_scores, yerr=train_std,
label="Training Score", marker='o', alpha=0.7)
# テストデータのスコアをプロット(エラーバー付き)
plt.errorbar(max_depths, test_scores, yerr=test_std,
label="Validation Score", marker='s', alpha=0.7)
# グラフの装飾
plt.title('GridSearch Results: Training vs Validation Scores')
plt.xlabel('Max Depth')
plt.ylabel('AUC Score')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()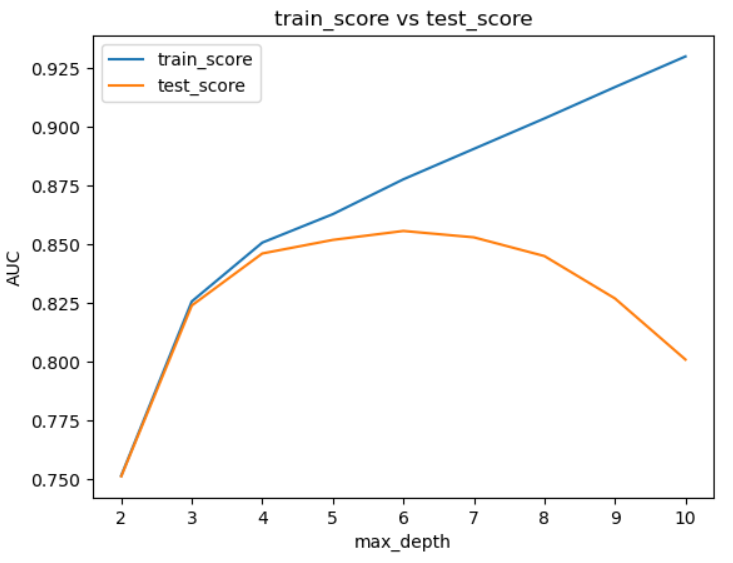
結果の解釈方法:
- 学習スコアが上昇し続ける:モデルが複雑になっている
- 検証スコアが途中で下降:過学習が発生
- 両スコアの差が大きい:汎化性能に問題あり
学習用データはmax_depthが大きくなるほどスコアが改善していますが、テスト用データでは途中から悪化しています。これはまさに学習用データにだけ適合した過学習が起こっており、その様子がよくわかりますね。
最適パラメータの取得と活用
最適なパラメータとモデルを取得し、実際に予測に使用します。
# 最適なパラメータの確認
print("最適なパラメータ:", gcv.best_params_)
print("最適なクロスバリデーションスコア:", gcv.best_score_)
# 最適なパラメータで学習したモデルを取得
optimal_model = gcv.best_estimator_
# 最適なモデルを用いて、テストデータの予測を行う
predicted_proba = optimal_model.predict_proba(test_X)[:, 1]
# 予測結果を用いてAUCを計算
test_auc_score = roc_auc_score(test_y, predicted_proba)
print(f"テストデータでのAUCスコア: {test_auc_score:.4f}")出力例:
最適なパラメータ: {'max_depth': 6}
最適なクロスバリデーションスコア: 0.8532
テストデータでのAUCスコア: 0.8456
先ほどのグラフの通りmax_depthが6の時がベストで、その際のAUCスコアも表示されました。
応用例:複数パラメータ・他アルゴリズムでの活用
LightGBMでの複数パラメータ探索
決定木以外のアルゴリズムでも、同様にGridSearchCVを活用できます。LightGBMを例に、複数パラメータの最適化を見てみましょう。
# LightGBMのインポート
import lightgbm as lgb
# LightGBMモデルの準備
lgbm = lgb.LGBMClassifier(random_state=0, verbose=-1)
# 複数パラメータの設定
parameters = {
'max_depth': [6, 8, 10], # 木の最大深度
'min_data_in_leaf': [20, 30, 40], # 葉ノードの最小データ数
'num_leaves': [20, 30, 40], # 葉の数
'learning_rate': [0.05, 0.1, 0.15] # 学習率
}
print(f"探索する組み合わせ数: {3*3*3*3} = 81通り")
# グリッドサーチの設定(時間短縮のためcv=3に変更)
gcv_lgbm = GridSearchCV(
estimator=lgbm,
param_grid=parameters,
cv=3, # 計算時間短縮のため3分割
scoring='roc_auc',
return_train_score=True,
n_jobs=-1, # 並列処理で高速化
verbose=1 # 進捗を表示
)
# グリッドサーチの実行
gcv_lgbm.fit(train_X, train_y)
print("LightGBMでの最適パラメータ:", gcv_lgbm.best_params_)
print("最適スコア:", gcv_lgbm.best_score_)計算時間の考慮と効率化のコツ
複数パラメータでのグリッドサーチは計算時間が長くなりがちです。効率化のテクニックを紹介します。
import time
from sklearn.model_selection import ParameterGrid
# パラメータグリッドのサイズを事前に確認
param_grid = {
'max_depth': [6, 8, 10, 12],
'min_data_in_leaf': [20, 30, 40, 50],
'num_leaves': [20, 30, 40]
}
total_combinations = len(ParameterGrid(param_grid))
print(f"総組み合わせ数: {total_combinations}")
# 推定実行時間の計算(1組み合わせあたり30秒と仮定)
estimated_time = total_combinations * 30 / 60 # 分単位
print(f"推定実行時間: {estimated_time:.1f}分")
# 効率化のための設定
gcv_efficient = GridSearchCV(
estimator=lgbm,
param_grid=param_grid,
cv=3, # 分割数を減らす
scoring='roc_auc',
n_jobs=-1, # 並列処理
verbose=2, # 詳細な進捗表示
pre_dispatch='n_jobs' # メモリ使用量の最適化
)
# 実行時間を測定
start_time = time.time()
gcv_efficient.fit(train_X, train_y)
execution_time = time.time() - start_time
print(f"実際の実行時間: {execution_time/60:.1f}分")効率化のコツ:
- 段階的探索:粗い範囲で探索後、細かい範囲で再探索
- 並列処理:
n_jobs=-1で全CPUを活用 - CV分割数調整:計算時間と精度のバランスを考慮
- パラメータ数制限:一度に最適化するパラメータは3-4個まで
よくあるエラーと対処法
スコアリング指標の選び方
適切な評価指標の選択は、グリッドサーチの成功に重要です。
# 問題タイプ別の推奨スコアリング指標
# 【分類問題】
classification_scores = {
'accuracy': '基本的な精度(バランスの取れたデータ)',
'roc_auc': 'AUC値(不均衡データにも対応)',
'f1': 'F1スコア(精度と再現率のバランス)',
'precision': '精度重視',
'recall': '再現率重視'
}
# 【回帰問題】
regression_scores = {
'neg_mean_squared_error': '平均二乗誤差(MSE)の負値',
'neg_mean_absolute_error': '平均絶対誤差(MAE)の負値',
'r2': '決定係数(説明可能な分散の割合)'
}
# 実際の使用例
# 不均衡データの分類問題の場合
gcv_imbalanced = GridSearchCV(
estimator=tree,
param_grid=parameters,
cv=5,
scoring='f1', # 不均衡データにはF1スコアが適切
return_train_score=True
)メモリ不足・時間超過への対策
大規模データやパラメータでのグリッドサーチ時の対処法を説明します。
データの前処理についてはscikit-learnでのデータ分割方法も参考にしてください。
# 【対策1】データサンプリング
from sklearn.model_selection import train_test_split
# 大規模データの場合、サンプリングしてグリッドサーチ
if len(train_X) > 50000:
sample_X, _, sample_y, _ = train_test_split(
train_X, train_y,
train_size=0.3, # 30%をサンプリング
random_state=42,
stratify=train_y # 分類の場合は層化抽出
)
print(f"サンプリング後のデータサイズ: {len(sample_X)}")
else:
sample_X, sample_y = train_X, train_y
# 【対策2】段階的パラメータ探索
# まず粗い範囲で探索
coarse_params = {
'max_depth': [5, 10, 15, 20],
'min_samples_split': [10, 50, 100]
}
gcv_coarse = GridSearchCV(tree, coarse_params, cv=3, scoring='roc_auc')
gcv_coarse.fit(sample_X, sample_y)
# 最適値周辺で細かく探索
best_depth = gcv_coarse.best_params_['max_depth']
fine_params = {
'max_depth': [best_depth-2, best_depth-1, best_depth, best_depth+1, best_depth+2],
'min_samples_split': [40, 50, 60]
}
print(f"粗探索の最適値: {gcv_coarse.best_params_}")よくある質問と解決法
Q: GridSearchCVの実行に時間がかかりすぎます
# A: 以下の設定で高速化を図りましょう
gcv_fast = GridSearchCV(
estimator=model,
param_grid=param_grid,
cv=3, # 分割数を減らす
n_jobs=-1, # 並列処理
pre_dispatch='2*n_jobs', # メモリ効率化
verbose=1 # 進捗確認
)Q: best_params_とbest_estimator_の違いは?
# A: 使い分けは以下の通りです
print("最適パラメータ(辞書):", gcv.best_params_)
print("最適モデル(学習済み):", type(gcv.best_estimator_))
# best_params_: パラメータの辞書 → 新しいモデルの設定に使用
# best_estimator_: 学習済みモデル → そのまま予測に使用可能Q: クロスバリデーションの分割数はどう決める?
# A: データサイズと計算時間のバランスで決めます
import numpy as np
data_size = len(train_X)
if data_size < 1000:
recommended_cv = min(5, data_size // 100)
elif data_size < 10000:
recommended_cv = 5
else:
recommended_cv = 3
print(f"データサイズ {data_size} に対する推奨CV分割数: {recommended_cv}")まとめ
本記事では、PythonのGridSearchCVを使ったハイパーパラメータ最適化について、基本的な使い方から実践的な応用例まで詳しく解説しました。
重要なポイント:
- ✅ GridSearchCVは全探索による確実な最適化が可能
- ✅ 適切なパラメータ範囲設定が成功の鍵
- ✅ 計算時間とのバランスを考慮した設定が重要
- ✅ 結果の可視化でモデルの挙動を理解
- ✅ 段階的探索で効率的な最適化が可能
この記事を通じて、より高性能な機械学習モデルの構築にお役立ていただければ幸いです。GridSearchCVを効果的に活用して、データサイエンスプロジェクトの成功を目指しましょう!


