
Pandasのrank関数は、データの順位を簡単に計算できる便利なツールです。この記事では基本的なランクの計算方法から、整数での表示、特定の列を指定したランクの計算方法まで、rank関数の使い方を解説します。
Pandasのrank関数の基本的な使い方
rank関数は、PandasのDataFrameやSeriesオブジェクトに対して、データの順位を計算するための関数で、以下のような用法となります。
DataFrame.rank(axis=0, method='average', numeric_only=None, na_option='keep', ascending=True, pct=False)
各パラメータの説明とデフォルト値を具体例を交えて解説します。
Pandasで特定の列を指定してランクを計算する基本的な方法
シンプルなデータセットを用いて、rank関数の基本的な使用方法を示します。以下のコードは、学生のスコアに基づいてランクを計算し、新しい列としてDataFrameに追加します。
import pandas as pd
data = {'Score': [90, 85, 77, 95, 88]}
df = pd.DataFrame(data)
df['Rank'] = df['Score'].rank(ascending=False)
print(df)
このコードを実行すると、スコアに基づいたランクが計算され、新しい列として追加されます。
Pandasのrank関数で整数のランクを表示する方法
methodパラメータを'min'や'max'に設定すると、ランクが整数で表示されます。以下のコードは、同じスコアを持つ学生に最小の整数ランクを割り当てます。
df['Integer Rank'] = df['Score'].rank(method='min', ascending=False).astype(int)
よくあるエラーやトラブルシューティング
rank関数使用時によく遭遇するエラーや問題点とその解決策を紹介します。
NaN値の取り扱い
- 問題: データセットにNaN値が含まれている場合、
rank関数のデフォルトの挙動はNaN値にランクを割り当てません。 - 解決策:
na_optionパラメータを使用して、NaN値のランクの扱いを制御します。 - コメント: NaN値をデータセットの最下位として扱いたい場合は、
na_option='bottom'を設定します。
df['Rank with NA'] = df['Score'].rank(na_option='bottom')
データ型の不整合
- 問題: データセットの中に文字列や日付など、数値でないデータが含まれている場合、
rank関数はエラーを返すことがあります。 - 解決策: データセットの対象列を数値型に変換します。
- コメント:
df['Score'] = pd.to_numeric(df['Score'], errors='coerce') # <strong><code>errors='coerce': 数値に変換できない値がある場合、それらの値をNaN(Not a Number)に置き換えます。
methodパラメータの誤用
- 問題:
methodパラメータの設定が不適切であると、同じスコアのデータに対するランクの振り方が期待と異なる場合があります。 - 解決策:
methodパラメータを適切な値(’average’, ‘min’, ‘max’, ‘first’, ‘dense’)に設定します。 - コメント:以下のコードは、同じスコアのデータに対して、データが現れた順に異なるランクを割り当てます。
df['Score'].rank(method='first')-
‘average’
- 同じスコアを持つデータに対して、そのランクの平均値を割り当てます。
- 例:スコアが [10, 20, 20, 30] の場合、ランクは [1, 2.5, 2.5, 4] になります。
-
‘min’
- 同じスコアを持つデータに対して、そのグループの最小のランクを割り当てます。
- 例:スコアが [10, 20, 20, 30] の場合、ランクは [1, 2, 2, 4] になります。
-
‘max’
- 同じスコアを持つデータに対して、そのグループの最大のランクを割り当てます。
- 例:スコアが [10, 20, 20, 30] の場合、ランクは [1, 3, 3, 4] になります。
-
‘first’
- 同じスコアを持つデータに対して、データが現れた順に異なるランクを割り当てます。
- 例:スコアが [10, 20, 20, 30] の場合、ランクは [1, 2, 3, 4] になります。
-
‘dense’
- 同じスコアを持つデータに対して、同じランクを割り当て、次のランクはその次の整数になります(ランクにギャップがない)。
- 例:スコアが [10, 20, 20, 30] の場合、ランクは [1, 2, 2, 3] になります。
Pandasで特定の列を指定して他の列をランク付けする方法
次に特定の列の値に基づいて、他の列のデータをランク付けする方法を紹介します。これは例えば、あるテストのスコアに基づいて、生徒の成績をランク付けしたい場合などに使用します。
以下は生徒の数学のテストスコアに基づいて、英語のテストスコアをランク付けするシンプルな例です。
import pandas as pd
# サンプルデータの作成
data = {
'Student': ['Alice', 'Bob', 'Charlie', 'David'],
'Math_Score': [90, 85, 77, 92],
'English_Score': [88, 79, 92, 85]
}
df = pd.DataFrame(data)
# Math_Scoreを基準にして、English_Scoreのランクを計算
df['English_Rank'] = df['English_Score'].rank(ascending=False)
# Math_Scoreの値に基づいて、English_Rankをソート
df = df.sort_values(by='Math_Score', ascending=False)
print(df)
このコードを実行すると、数学のスコアに基づいて、英語のスコアがランク付けされ、新しい列として追加されます。そして、数学のスコアでデータがソートされます。
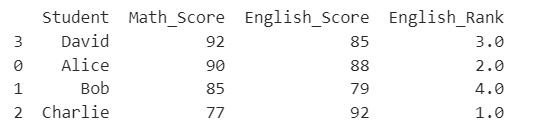
この例ではMath_Score列を基準にしてEnglish_Scoreのランクを計算し、その結果を新しい列English_Rankに保存し、最後にMath_Scoreの値でソートしています。
以上、ランク関数について説明しました。
特にmethodについては理解しておかないと想定と違う順位付けを行う可能性があるので、「複数の種類がある」ということは認識しておく必要があると思います。


